Disruptor介绍
大部分内容翻译自Disruptor在github上的wiki
介绍
LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动方式。业务逻辑处理器的核心是Disruptor。
在介绍Disruptor的时候,通常会将其和 java 里的队列进行对比。Disruptor和队列的目的大致类似,Disruptor的目的是在线程间传递数据(或者消息)。而Disruptor和队列相比主要有以下几点区别:
- 消息可以广播到多个消费者,即一个消息可以被多个消费者处理
- 为消息提前分配内存
- 一定条件下的无锁化
几个核心概念
在介绍Disruptor的运行方式以前,有几个比较重要的概念需要先介绍一下:
环形缓冲区(Ring Buffer):环形缓冲区是Disruptor里最重要的一个概念,它负责数据(或者消息)的存储和更新。同时环形缓冲区同样可以被用户使用另外的数据结构来代替。
序列号(Sequence):Disruptor使用序列号来标识每个消费者当前的消费的状态。每个消费者都持有一个序列号,Disruptor本身也持有序列号。Disruptor中大部分的并发逻辑都依赖于序列号的变更。Disruptor中的序列号与java中的AtomicLong的实现类似,唯一的区别在于Disruptor中的序列号的实现多了一部分避免伪共享的逻辑以期望提升性能。
序列器(Sequencer):Sequencer是Disruptor的真正核心,它的作用是整合所有的序列号,确定消息生产或者消费的具体顺序,它是Disruptor的高效性和准确性的基石。
序列屏障(Sequence Barrier):序列号屏障是由序列器创建的对象,它包含了当前生产者的序列号和消费者的序列号的引用,它的作用是确定一个消息何时可以被消费者消费。
等待策略(Wait Strategy):等待策略决定了消费者在等待可用消息时的行为,可选的策略包括让出CPU时间、自旋等等。
消息(Event):消息即生产者和消费者之间传递的对象,在Disruptor中没有具体实现,由用户自己实现。
消息处理器(EventProcessor):消息处理器是一个事件循环(Event Loop),它持有消费者的序列号,主要负责从Disruptor获取可用的消息进行处理。Disruptor提供了一个BatchEventProcessor,用于批量获取消息然后调用用户提供的消息逻辑处理器(EventHandler)进行处理。
消息逻辑处理器(EventHandler):Disruptor定义的接口,实现了消息的消费逻辑,由用户自己实现。
LMAX使用Disruptor的示意图
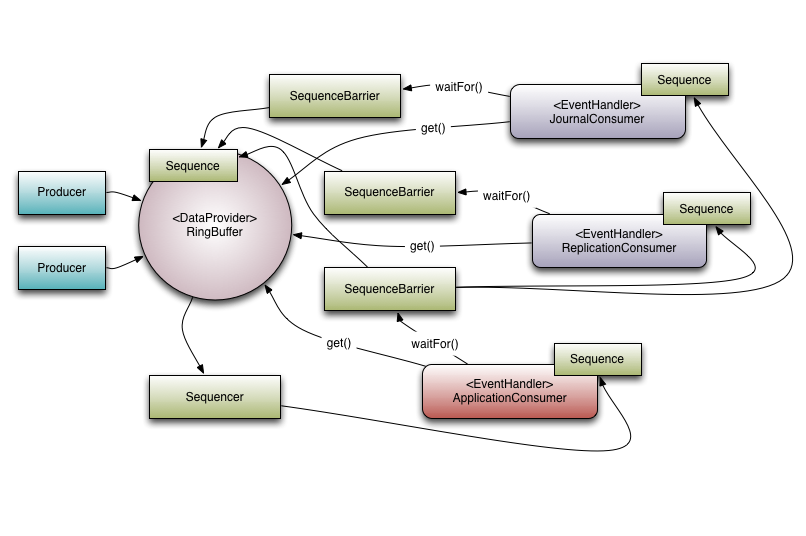
消息多播
消息多播是Disruptor与队列的一个主要的区别。当一个Disruptor实例被多个消费者监听时,所有的消息都会被传递给每一个处于监听状态的消费者,而在队列中一份数据只会被传递给一个消费者。这样设计的目的是方便在同一份数据上进行多种并行的操作。在LMAX的实际运用中,一份数据上会执行三个操作:日志(将数据写入持久性存储的日志文件中)、备份(将数据发送到另一台机器以实现冗余备份)以及真正的业务逻辑。Disruptor通过Executor风格的事件处理方式来并行处理事件来达到扩展性,同样的并行处理逻辑也可以通过WorkerPool来实现,但Disruptor并不推荐这种方式,因为WorkerPool的实现方式并不高效。
在LMAX使用Disruptor的示意图可以看到,一共有三个EventHandler,而每一个EventH都获得了所有的可用的消息,而他们各自的逻辑都是并行执行的。
消费者间的相互依赖
为了支持真正的并行处理,Disruptor必须支持消费者之间的相互协调。比如上述的例子当中,真正的业务逻辑实际上必须等待日志逻辑和备份逻辑完成之后才能开始。在Disruptor里叫做门控(Gating),在Disruptor中门控主要发生在两个地方:一个是确保生产者不会覆盖环形队列上尚未被消费的逻辑,这个功能通过在RingBuffer上调用addGatingComsumer方法实现;另一个就是上面的例子里说到的情况,这个功能通过构建一个包含前两个消费者的序列号的序列屏障来实现。
以上图为例,ApplicationConsumer依赖于ReplicationConsumer和JournalConsumer,这个依赖关系存放在ApplicationConsumer持有的序列屏障当中。ReplicationConsumer和JournalConsumer可以并行处理缓冲区里的消息。同时序列器(Sequencer)与消费者中的下游消费者的关系也值得注意,序列器的另一个作用就是避免环形缓冲区重叠,要达到这个目的,必须确保序列器的序号减去任意一个消费者的序列号的差值不超过环形队列的容量。而消费者间的依赖关系还有另一个有趣的作用,我们可以通过依赖关系来优化序列器的等待策略,即序列器不需要关注每个消费者,而只需关注消费者依赖树中的叶子节点的序列号即可。
消息的预分配
Disruptor的一个目标就是追求低延迟。而为了追求低延迟,就需要尽可能减少甚至避免内存的分配。在基于java的系统中,就是要尽量减少垃圾回收时间(即使在低延迟的C/C++系统中,由于存在于内存分配器上的争用,频繁的内存分配也会导致问题的)。
在Disruptor中,用户可以预先分配用于存储消息的内存空间。Disruptor在构造环形缓冲区是会创建若干个默认对象来将缓冲区填满,生产者在生产消息时可以从缓冲区中指定位置上存放的对象并对其进行修改。Disruptor会确保在正确使用的情况下,这些操作都是并发安全的。
一定条件下的无锁化
追求低延迟所带来的另一个特性就是Disruptor内部的大量无锁化逻辑。所有变量的内存可见性和正确性都通过内存屏障(volatile)和CAS(compare-and-swap )算法实现。Disruptor中唯一一处用到锁的逻辑就是在BlockingWaitStrategy的实现当中。这样实现的唯一目的是在于能通过使用Condition类让消费者线程可以在等待过程中主动挂起,它适用于CPU资源比较紧张的环境。许多追求低延迟的系统会采用忙等的策略来避免使用Condition类可能带来的抖动。忙等的策略是指消费者采用忙自旋的方式等待可用消息,避免因线程切换带来的延迟。但是在某些情况下忙等策略反而会导致性能下降,特别是在CPU资源紧张的环境,例如在虚拟机上运行的webserver。