如何设计一个分布式任务调度系统
前言
定时任务作为业务当中常见的场景,在此前很长一段时间都是通过 kuaishou-framework 中提供的 ScheduledTask 支持的。ScheduledTask 的实现比较简单,总的来说就是 zk 锁 + 定时线程池:zk 锁用于保证实例间互斥,即同一时间只有一个进程在运行;定时线程池则用于定时触发业务逻辑。
随着公司业务规模的发展壮大,一个简单的 ScheduleTask 已经无法满足开发人员日益增长的业务开发和维护需求了,因此我们决定就这个机会建设一个全新的分布式任务调度解决方案(下文称作任务调度平台或者调度平台)。
需求整理
在进行设计之前,这里先简单列举此前收集到的各项定时任务相关的需求。
功能性需求:
- 提供一个可视的控制台
- 支持展示任务当前的运行状态:机器列表、历史记录等
- 支持动态修改任务属性:触发频率、额外参数等
- 支持监控报警
非功能性需求:
- 可靠性,即不会漏触发或者重复触发
- 时效性,即在准确的时刻触发,不早也不晚
- 易用性
业界产品
他山之石可以攻玉,在进行系统设计之前我们可以先了解一下业界的其他产品,这里简单列举几个调研期间参考的产品:
- Quartz:老牌的任务调度框架,功能丰富而且灵活,支持单机或集群运行
- Elastic Job:开源的任务调度产品,特点是支持任务分片运行,此外还提供了基于 Mesos 的 cloud 版本。值得一提的是在停止更新许久之后最近又开始作为 ShardingSphere 的子项目活跃起来。
- xxl-job:一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
- SchedulerX:阿里中间件自研的基于 Akka 架构(Akka in SchedulerX 2.0)的新一代分布式任务调度平台,提供定时、任务编排、分布式跑批等功能,具有高可靠、海量任务、秒级调度及可运维等能力。
设计思路
中心化调度
原始的 ScheduledTask 采使用的是去中心化的实现,实例间的协调以及运行频率都在固定在业务进程中,要做修改时必须修改代码然后重启进程。这样的优势是实现简单,但是对组件的控制比较弱,要对协调逻辑做修改的成本比较高。
所以在新的任务调度平台建设时,我们决定采取中心化的调度方式,所有的协调逻辑以及任务参数(运行频率等)都由调度平台维护,用户只需要实现核心的任务逻辑然后通过 SDK 接入即可。这样的好处在于维护者和使用者对定时任务的控制更强,协调逻辑可以随时更新,用户可以通过平台动态的调整任务属性,但是对维护者的要求更高,所以也就要求我们在设计和实现时尽可能考虑的更加周全,尽可能提高平台自身的可靠性,同时降低平台的维护成本。
server - client 模式
确定了中心化调度的思路,也就是确定了“调度与运行分离”的思路。“运行”这一过程在原始的 ScheduledTask 的实现中是位于用户的进程中的,在建设新的任务调度平台时也需要考虑同样的问题,是把执行逻辑直接放到用户进程,还是使用统一的机器资源来执行用户逻辑。结合公司当前的情况,我们决定采取两步走的方式:中短期内通过用户进程执行,长期目标是通过统一的托管的机器资源来执行,用户只需提交代码即可。
因此我们的任务调度平台的运行模式是 server-client 模式,任务调度平台作为 server 负责定时下发执行任务的命令到作为 client 的用户进程中的 SDK,SDK 在收到命令之后再出发业务逻辑。当任务执行完毕时,SDK 再将执行结果上报给调度平台,调度平台将结果记录之后再根据情况发送报警等。
基于 grpc 的通信
在任务的定时运行过程中,我们可以看到有多次调度平台与 SDK 之间的通信,在通信方式的选型上,我们选择了 grpc,实际上除了 grpc 之外也有很多其他可选项,比如 http 或者 mq,最终选择 grpc 的原因第一在于我们本身有使用经验,同时公司现有的 grpc 提供了超时重试等控制逻辑,能够降低后续的开发和维护成本。
由于目前 grpc 并不支持双向调用,所以在具体实现中调度平台和 SDK 各自都会监听端口。
调度模块无状态
我们采用中心化的调度方式,所有就需要有一个专门的“调度模块”来负责任务命令的下发。而为了保证命令下发的可靠,调度模块的实例需要保证无状态,这样可以在单个实例发生故障时可以快速转移到其他实例,同时也可以支撑实例的水平扩展来提高服务容量。
调度模块的主要职责可以分为两部分:根据任务信息计算触发时间、在适当的时间向客户端下发任务命令。所以我们可以通过分片机制把所有的任务映射到调度模块的不同实例,每个实例只负责处理计算和触发一部分任务;当实例出现宕机或者重启时,这个实例负责的任务应该及时转移到其他实例。
因此我们的结论就是为了使调度模块无状态,我们需要:
- 将全量任务映射到不同调度模块实例的分机制
- (准)实时的检查调度模块实例的健康状况的机制
基于虚拟槽位(slot)的映射机制
为了将全量任务映射到不同调度模块实例,我们参考了 redis cluster 的设计思路,将每个任务根据任务名哈希映射到某个虚拟槽位(slot) 上,再将 slot 分配给各个调度模块实例,每个实例就可以只处理自身对应的 slot 下对应的任务。而当有实例出现宕机或者重启时,就需要及时重新分配 slot。
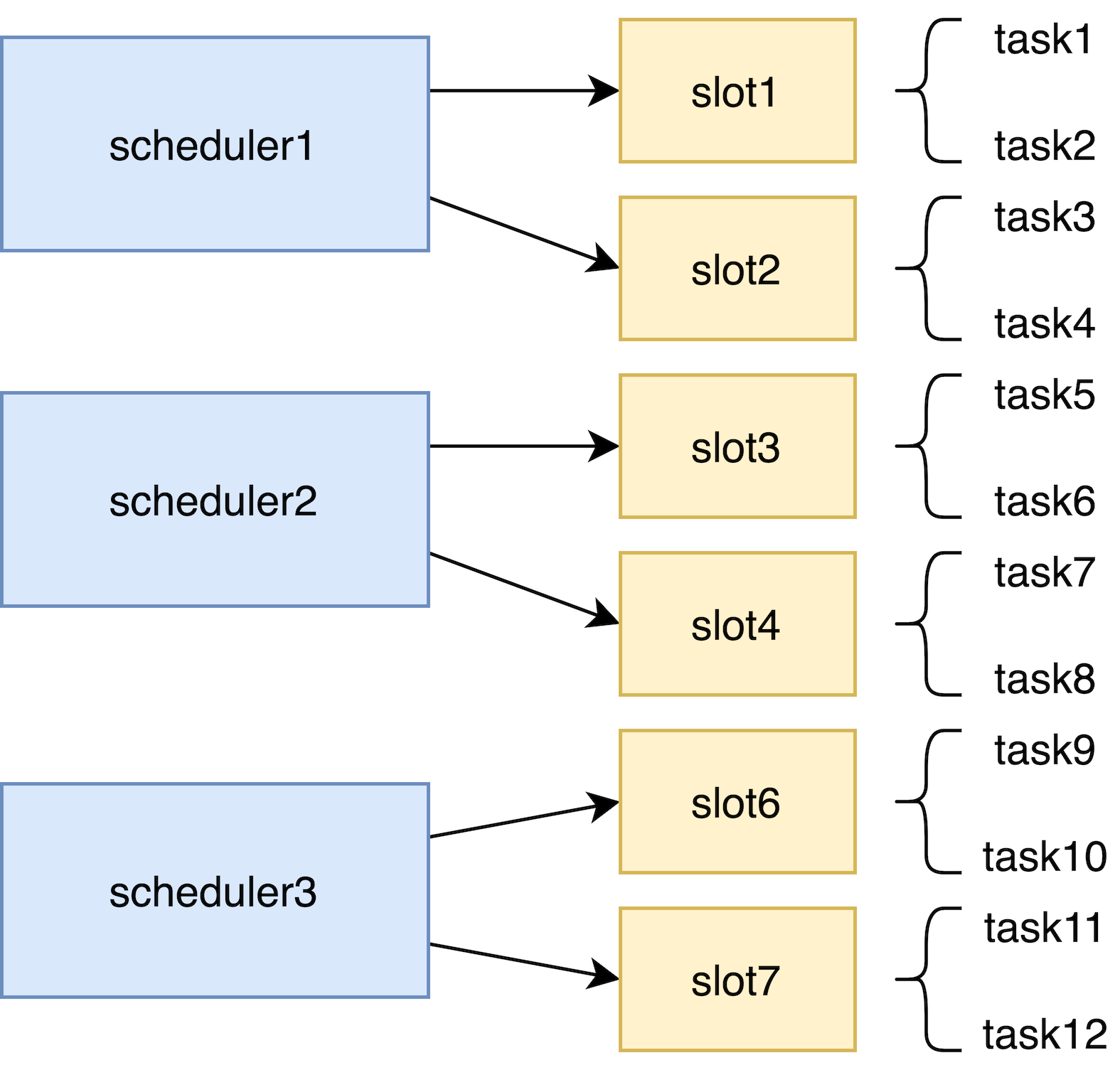
基于 kess 和主动探测的健康检查
我们把所有的任务都分配到不同的调度模块实例处理,就需要在实例变化(宕机或者更新)时重新分配 slot 和实例的映射关系。 这样我们就需要维护一个实例列表,当实例列表变化时重新分配即可。
非常幸运的是公司有 kess 这样的提供注册中心功能的组件(不然可能就需要 zookeeper 或者是 etcd 了),我们可以直接将每个实例都注册到 kess 并且对 kess 进行监听即可。同时由于 kess 对实例的有效性检测是通过实例主动上报的心跳完成的,为了进一步提高对实例变化感知的时效性,我们可以再额外的进行主动健康检查,这里同样通过 grpc 来实现。
提前下发
值得注意的是,即使加上健康检查,也无法完全实时的感知实例的变化,再加上从感知到实例变化到重新分配完成再到新的分配结果下发到各个实例,这个过程仍是需要时间的。所以为了避免“刚好在需要触发任务的时刻对应实例宕机了”的情况,我们需要一定的“准备时间”,也就是提前一段时间将命令下发到客户端,这样的好处在于可以避免前面提到的实例刚好宕机的情况,而坏处则在于提前下发的命令可能会遇到“达到触发时间之前客户端就宕机或者重启”的情况,这种情况下对应的命令可能就会丢失。
所以我们需要选择一个合适的“准备时间”,在当前的场景下具体是 10 秒。目前来看这个值基本能够满足“避免调度实例或者客户端宕机”的要求,后续也可以根据实际情况做调整。
总体架构
最后附上整个平台的总体架构图,系统主要有三个模块组成:portal, manager 以及 scheduler。
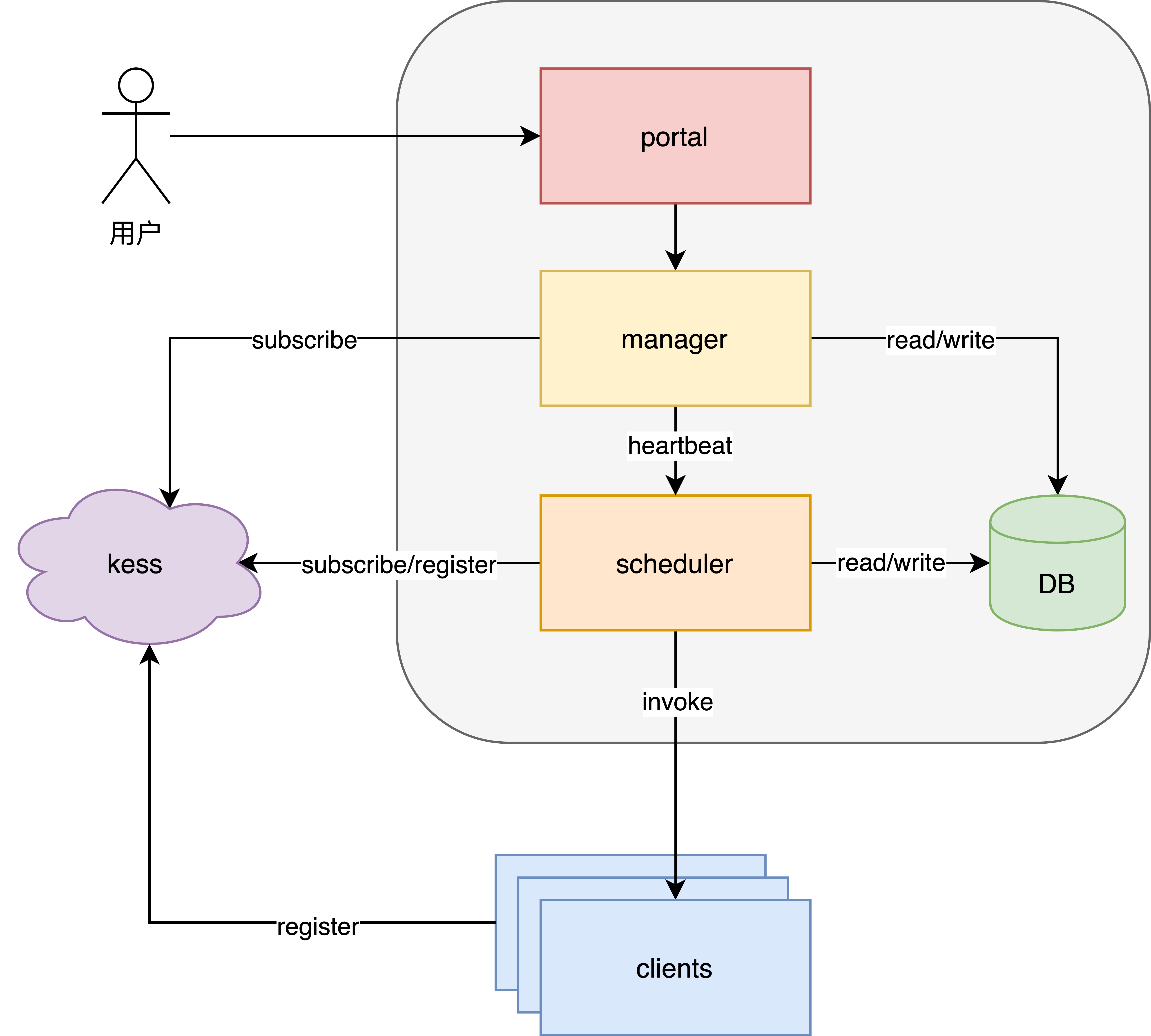
模块划分
| 模块名 | 说明 |
|---|---|
| portal | 面向用户,通过可视化的操作界面进行任务的查看和管理 |
| manager | 负责管理和协调 scheduler 模块的 slot 分配 |
| scheduler | 任务触发模块,负责计算任务触发时间并通知客户端执行 |
| client | 负责接收来自 scheduler 模块的命令并执行业务逻辑,运行在业务的进程中 |
| DB | 负责任务信息、历史记录、slot 分配记录等信息的存储 |
| kess | 注册中心,client 和 scheduler 都会进行注册 |
最后
本文简单介绍了任务调度平台在设计和实现阶段的一些思路,如果有想了解更多具体细节或者对文中介绍的内容有疑问或者建议的同学,欢迎在评论区或者 kim 上提出意见、一起交流。