Netty源码之ByteBuf
简介
ByteBuf类似于JDK里的ByteBuffer,但JDK里的ByteBuffer有几个局限性,如固定长度、需要手动flip等,所以Netty提供了类似ByteBuffer的实现ByteBuf。
与ByteBuffer 类似,ByteBuf提供以下几类基本功能:
- Java基础类型、数组、ByteBuf的读写操作
- 缓冲区自身的copy和slice
- 设置网络字节序
- 构造缓冲区实例
- 操作读写索引
ByteBuf与ByteBuffer的不同之处主要有以下两点:
- ByteBuf用两个位置指针来协助读写操作。读操作用readerIndex,写操作用writerIndex。读操作不会修改writerIndex,写操作不会修改readerIndex,简化了操作,避免了忘记flip而导致的异常。
- ByteBuf可以动态扩容。在对JDK里的ByteBuffer进行put操作时,通常需要检查剩余空间,如果剩余空间不够时还需要创建新的ByteBuffer,再进行复制操作,然后释放旧的ByteBuffer。而ByteBuf在写操作里包含了检查剩余空间和动态扩容的逻辑,当ByteBuf剩余空间不足时会自动扩充,而使用者无需关心实现细节。
由于NIO操作中的参数都是ByteBuffer,所以ByteBuf内部包含一个ByteBuffer的引用,用来表示对应的ByteBuffer。
部分功能介绍
顺序读(read) ByteBuf的read操作类似于ByteBuffer的get操作
顺序写(write) ByteBuf的write操作类似于ByteBuffer的put操作
readerIndex和writerIndex ByteBuf提供了两个指针变量用于支持顺序读取和写入操作:readerIndex用于标示读取索引,writerIndex用于标示写入索引,整个缓冲区被这两个索引划分为三个区域,如下图:
+-------------------+------------------+------------------+
| discardable bytes | readable bytes | writable bytes |
| | (CONTENT) | |
+-------------------+------------------+------------------+
| | | |
0 <= readerIndex <= writerIndex <= capacity
在调用ByteBuf的read操作时,从readerIndex处开始读取,readerInex与writerIndex之间的部分为可读缓冲区,writerIndex到capacity之间的部分为可写入缓冲区,0到readerInex之间为已读缓冲区。已读部分可以通过discardBytes来重用以节约内存,但这个操作会触发字节数组的内存复制,所以频繁调用会使性能下降。
readableBytes和writableBytes 可读空间是数据实际存放的区域,在ByteBuf上执行read或skip操作进行读取或者跳过指定数目的字节,会使readerIndex增加相应的数目。如果指定的读取长度大于可读字节数,则会抛出InexOutOfBoundsException。readerIndex在ByteBuf初始化时被初始化为0。可写空间是可以存放数据的空闲区域,调用write操作可以向空闲部分写入指定数目的字节,同时writerIndex增加。如果要写入的字节数大于可写字节数,则会抛出InexOutOfBoundsException。创建一个ByteBuf对象时writerIndex被初始化为0,用复制或包装的方式获得一个ByteBuf时,writerIndex为ByteBuf的容量。
clear操作 clear操作并不会清除缓冲区的内容,而是设置readerIndex和writerIndex为初始值。
mark和reset ByteBuf内部包含两个缓存的变量markedReaderIndex和markedWriterIndex。通过为这两个变量复制和将这两个变量赋给readerIndex和writerIndex来实现mark和reset操作。
查找
ByteBuf提供一系列方法来对缓冲区内字节进行查找或者遍历操作,使用者可以通过实现ByteBufProcesscor来自定义查找条件。

Derived buffers ByteBuf提供一系列方法来创建基于某个ByteBuf的视图或者复制ByteBuf,具体方法如下:
- copy():返回一个复制的ByteBuf对象,它的读写索引和缓冲区都是独立的,复制操作和对复制产生的对象进行修改不会影响原来的ByteBuf。
- copy(int index, int length): 与copy()类似,但可以指定复制的起始位置和要复制的长度。
- slice():返回当前ByteBuf可读部分的一个视图,从readerIndex到writerIndex。返回的ByteBuf对象与原ByteBuf共享内容,但各自独立维护自己的读写索引。该操作不会修改原ByteBuf的读写索引。
- slice(int index, int lenth): 与slice()类似,但可以指定视图的起始位置和长度。
- duplicate():返回当前ByteBuf的一个复制对象,返回结果与原ByteBuf共享内容,但各自独立维护自己的读写索引。当修改复制后的ByteBuf内容之后,原ByteBuf的内容也会改变,两个对象持有同一份内容的引用。
转换成标准ByteBuffer 在nio的SocketChannel进行读写的时候,使用的是ByteBuffer作为参数,由于Netty使用ByteBuf来取代ByteBuffer,所以必须支持ByteBuffer和ByteBuffer的互相转换。 将ByteBuf转换为ByteBuffer有两个方法:
- ByteBuffer nioBuffer():将当前ByteBuf的可读部分转换成ByteBuffer对象,两者共享同一个缓冲区内容引用。对ByteBuffer的读写不会影响ByteBuf的读写索引,同时ByteBuffer也无法感知ByteBuf后续的扩容操作。
- ByteBuffer nioBuffer(int index, int length) :与nioBuffer()类似,但可以指定缓冲区的起始位置和长度。
随机读写(set和get) 除了顺序读写操作以外,ByteBuf还支持指定位置的读写。但需要注意的是set和get操作不会触发自动扩容的逻辑,所以在调用随机读写操作前需要保证提供的位置索引合法,否则会抛出异常。
子类划分
ByteBuf部分子类结构图如下:
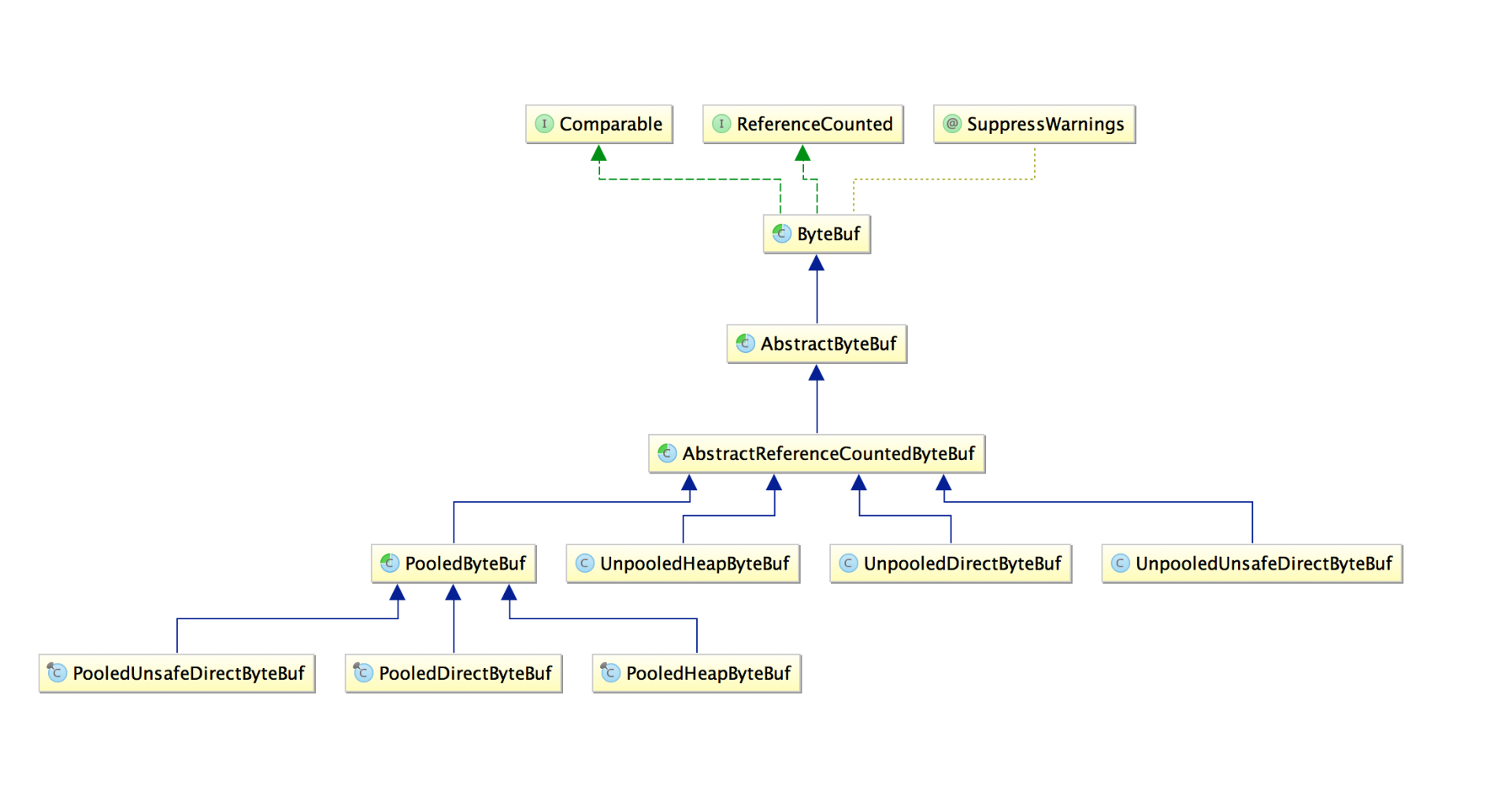
堆内存和直接内存
从内存分配的角度看,ByteBuf分为以堆内存为缓冲区和以直接内存为缓冲区两类。以堆内存为缓冲区的好处是分配和回收快,可以被java虚拟机自动回收;但缺点就是如果是进行Socket的IO操作,需要额外的内存复制操作,将缓冲区内容复制到内核channel中,会在一定程度上影响性能。以直接内存为缓冲区的好处是在Socket上进行读写操作时少了一次内存复制,速度比堆内存快;但缺点是分配和回收的速度会慢一些。
对象池和普通对象
从内存回收的角度看,ByteBuf分为基于对象池的ByteBuf和普通ByteBuf。这两者的区别就是基于对象池的ByteBuf可以重用已经创建的ByteBuf,提高内存利用率而避免高负载导致的频繁GC,但对象池需要额外的管理和维护,所以具体采用哪种实现应该根据具体情况灵活选择。
AbstractByteBuf源码分析
成员变量
static final ResourceLeakDetector<ByteBuf> leakDetector =
ResourceLeakDetectorFactory.instance().newResourceLeakDetector(ByteBuf.class);
int readerIndex;
int writerIndex;
private int markedReaderIndex;
private int markedWriterIndex;
private int maxCapacity;
private SwappedByteBuf swappedBuf;
可以看到AbstractByteBuf定义了一些子类所需要的公共变量,如读写位置索引,最大容量等。此外还有一个静态变量leakDetector,这个对象是用来检测对象是否泄漏的。AbstractByteBuf并没有定义数据缓冲区的具体实现,这个部分由具体的子类负责定义,如byte数组或者DirectByteBuffer。
读操作
公共功能由父类实现,而子类则负责实现一些差异化功能。
以readBytes(byte[] dst, int dstIndex, int length) 为例:
public ByteBuf readBytes(byte[] dst, int dstIndex, int length) {
checkReadableBytes(length);
getBytes(readerIndex, dst, dstIndex, length);
readerIndex += length;
return this;
}
首先调用checkReadableBytes方法检查是否有足够的内容可读,此处是根据读写索引来进行判断。检查完毕之后调用getBytes方法将可读缓冲区内容复制到给定的byte数组中,而getBytes是一个抽象方法,有不同的子类负责具体的实现。读取成功之后readerIndex相应增加length。
写操作
以writeBytes(byte[] src, int srcIndex, int length)为例:
public ByteBuf writeBytes(byte[] src, int srcIndex, int length) {
ensureAccessible();
ensureWritable(length);
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}
首先调用ensureAccessible方法来保证可达性,在任何试图修改缓冲区的操作前都需要进行这一步来确认缓冲区是否已经被释放了。然后调用ensureAccessible检查要输入的字节数,如果要写入的字节小于可写缓冲区则直接返回,否则进行缓冲区扩容,如果扩容到最大容量后仍不能满足要写入的长度则抛出IndexOutOfBounds异常。 ensureWritable的实现如下:
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format(
"minWritableBytes: %d (expected: >= 0)", minWritableBytes));
}
if (minWritableBytes <= writableBytes()) {
return this;
}
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
// 动态扩容
int newCapacity = calculateNewCapacity(writerIndex + minWritableBytes);
capacity(newCapacity);
return this;
}
再看ByteBuf动态扩容的实现: 先调用calculateNewCapacity方法来计算扩容后的容量大小,这个方法有一个参数,即为满足扩容要求的最小容量。
private int calculateNewCapacity(int minNewCapacity) {
final int maxCapacity = this.maxCapacity;
final int threshold = 1048576 * 4; // 设置扩容门限为4MB
if (minNewCapacity == threshold) {
return threshold;
}
// 如果超过了门限则每次按门限大小递增
if (minNewCapacity > threshold) {
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// 如果没有超过门限,则从64开始每次翻倍
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}
首先设置门限值为4MB,根据minNewCapacity和门限的大小来判断扩容逻辑:如果需要的新的容量大小为4M,则返回4M;如果新容量没有超过4M,则从64开始逐渐倍增,直到大于或等于新容量为止;如果新容量超过了4M,则每次步进4M,直到满足要求。在算出新的容量之后还需要和设定的最大容量比较,如果超过了最大容量则返回最大容量,否则返回计算出的新容量值。
之所以采用倍增加步进的算法,是因为如果直接用minNewCapacity作为新的容量值,那么本次写入之后可写缓冲区大大小为0,下一次写入则又需要动态扩容。设置门限的原因在于在初始值较小的时候采取倍增的方法不会有太大影响,但当增长到一定阈值之后,再进行倍增可能会带来额外的消耗。比如内存增长到了10M,而此时系统需要12M,如果再进行倍增的话就到达20M,就有8M的空间被浪费了。随着客户端连接的线性增长,内存浪费的大小也随之增长,内存消耗的成本会成比例的增加,所以需要在到达某个阈值之后进行平滑的扩张。而此处的门限值4M则是一个经验值,不同的应用场景可能不同。
在计算出新的容量之后,需要创建新的缓冲区并将当前缓冲区的内容复制到新的缓冲区中,即此处的capacity方法,该方法也是一个抽象方法。
重用缓冲区
前面提到过ByteBuf的缓冲区被两个位置指针分割为三个区域,在readerIndex以前的部分是已读部分,可以通过discardBytes来重用这部分缓冲区。
public ByteBuf discardReadBytes() {
ensureAccessible();
if (readerIndex == 0) {
return this;
}
if (readerIndex != writerIndex) {
setBytes(0, this, readerIndex, writerIndex - readerIndex);
writerIndex -= readerIndex;
adjustMarkers(readerIndex);
readerIndex = 0;
} else {
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
}
return this;
}
首先判断如果readerIndex为0,也就是没有已读的缓冲区,这时候直接返回。如果readerIndex和writerIndex相等,即所有的数据都被读取过了,这时候直接把readerIndex和writerIndex设为0,相当于重用整个缓冲区,但这时候并不会修改缓冲区内容。如果readerIndex和writerIndex不相等,那么整个ByteBuf缓冲区包含三个部分:已读部分、可读部分、可写部分,这时候调用setBytes进行内容复制,将可读部分复制到缓冲区起始,然后重新设置readerIndex和writerIndex。在设置读写索引的同时还需调用adjustMarkers方法正确地设置备份的markedReaderIndex和markedWriterIndex。
除了discardReadBytes以外,还有一个类似的方法discardSomeReadBytes(),这个方法的名字有些迷惑,它的具体功能与discardBytes大致一样,唯一的区别当缓冲区有未读部分时,他会判断readerIndex是否大于容量的一半,如果是则调用setBytes复制和重用缓冲区内容,否则什么也不做。
跳过字节
AbstractByteBuf还提供跳过某些字节的方法,该方法只有一个参数length,即要跳过的字节数,调用者需保证length参数的合法性,否则会抛出异常,该方法的具体实现就是将readerIndex增加length。
public ByteBuf skipBytes(int length) {
checkReadableBytes(length);
readerIndex += length;
return this;
}
其他子类
AbstractByteBuf有很多具体实现,比如UnpooledHeapByteBuf,它基于堆内存来分配缓冲区,其内部是一个byte数组,它的扩容和复制都使用是的System.arrayCopy方法,与UnpooledHeapByteBuf对应的还有UnpooledDirectByteBuf,它使用直接内存做缓冲区。此外还有基于对象池的PooledHeapByteBuf和PooledDirectByteBuf,它们的创建和销毁策略有所不同,其他的功能都是等同的。